Immer wieder liest man, dass Suchmaschinenoptimierung eigentlich gar nicht nötig ist. Eine Gute Webseite wird schon von Suchmaschinen gefunden, richtig bewertet und entsprechend gelistet.
Dann werden Suchmaschinenoptimierer meist noch ins Zwielicht gerückt und mit Spammern oder Hackern verglichen, die Suchmaschinen hinters Licht führen wollen. Vermeintliches Ziel von SEOs ist es doch, irgendeinen Werbeschrott möglichst weit oben in den Suchmaschinen-Ergebnissen (SERPs) zu positionieren. Noch ein paar Ausrufezeichen!!!!! zur Untermalung des eigenen Standpunkts und der perfekte Troll-Beitrag ist fertig.
Web-Designer bekommen bei dieser Art von Mensch meist auch noch ihr Fett weg. Eine gute Webseite designt man schließlich nur mit Notepad und reinem HTML ;) Aber das ist eigentlich ein anderes Thema …
Manchmal beneide ich Menschen mit einem solchen simplen Weltbild. Es ist sicherlich einfacher, wenn man die Welt nur in Schwarz oder Weiß einteilt. Eben in Gut und Böse.
Nachfolgend ein Beispiel was ohne Blick auf Suchmaschinenoptimierung mit einer guten und hilfreichen Webseite passieren kann:
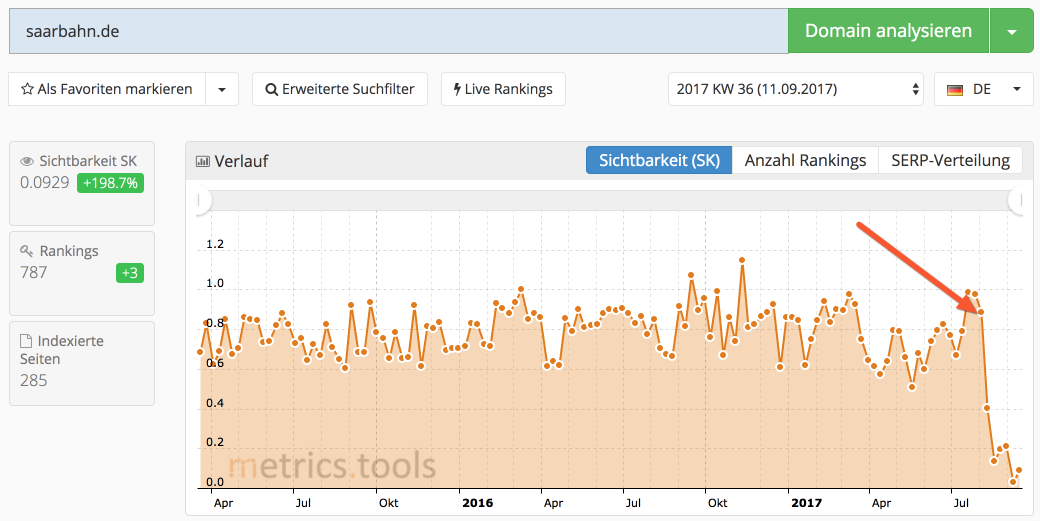
zwei Webseiten mit deutlichen Sichtbarkeitsverlust
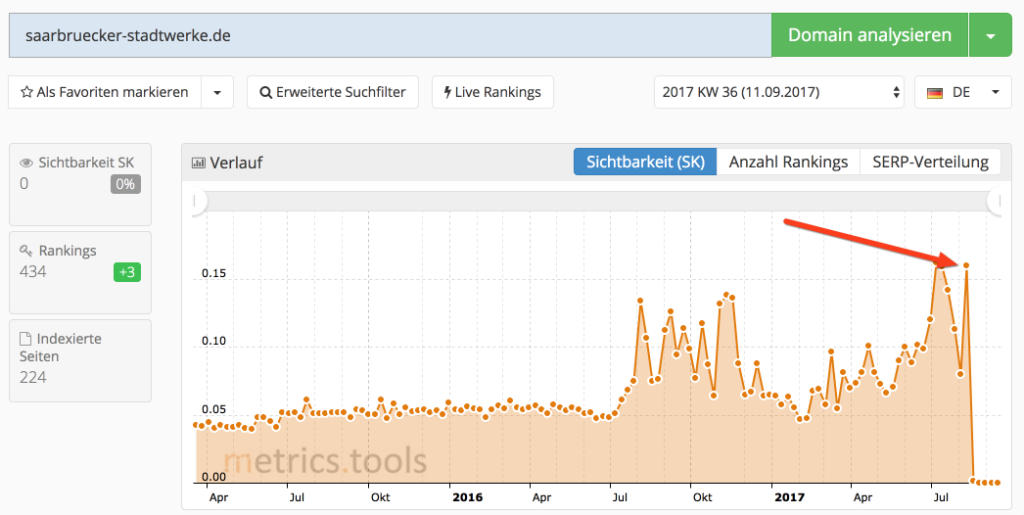
Es handelt sich um die beiden Webseiten der Saarbahn und der Saarbrücker Stadtwerke. Beide Webseiten sind nach aktuellem Stand (13.09.2017) kaum noch in Google zu finden.
Die Site-Abfrage in Google zeigt ein desaströses Bild:
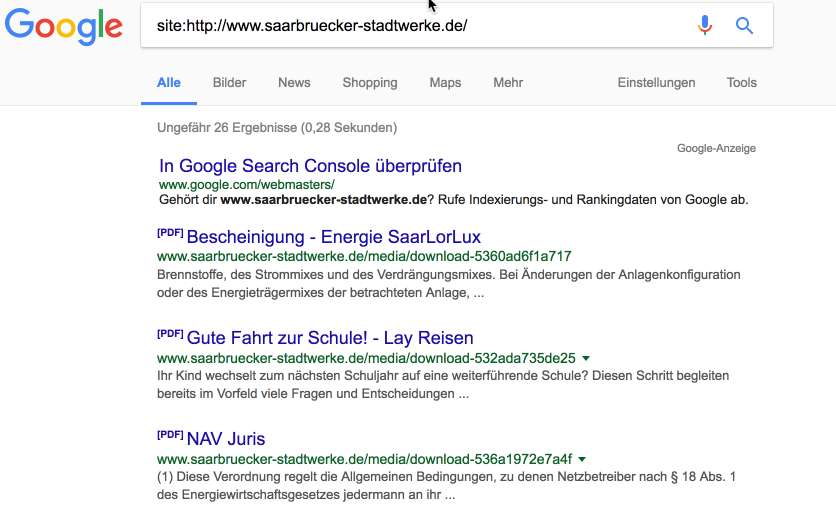
Nur noch ein paar PDF sind aktuell in Google gelistet.
Ein Blick auf die Sichtbarkeit (hier verwende ich die metrics.tools) zeigt für beide Webseiten einen fast kompletten Sichtbarkeitsverlust.
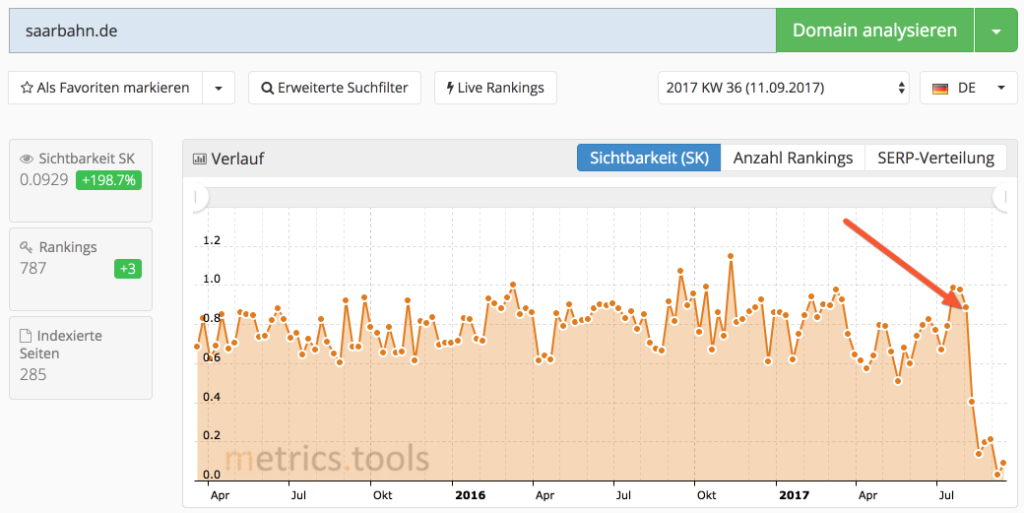
Im Fall von Saarbahn.de ist der Sichtbarkeitsverlust besonders schmerzhaft, da er in absoluten Zahlen sehr hoch ist.
Woran liegt der Sichtbarkeitsverlust?
Als Suchmaschinenoptimierer kann ich natürlich nicht anders, als der Ursache auf den Grund zu gehen.
Schnell fällt auf, dass die beiden Webseiten das gleiche Content Management System (CMS) und Design verwenden. Grund ist wahrscheinlich, dass die Saarbahn mit den Saarbrücker Stadtwerken verbandelt sind, aber darum geht es hier ja nicht.
Findet man also den Grund auf einer Webseite, dann hat man sehr wahrscheinlich auch den Grund für die andere Webseite gefunden.
In so einem Fall wie diesen, spricht vieles für einen technischen Fehler auf den Webseiten. Und zwar ein Fehler, der die komplette Seite betrifft, außer die PDF-Dateien. Meist liegt der Fehler im Bereich des CMS.
Für eine kurze SEO-Analyse, bietet sich folgendes Vorgehen an:
- Check der robots.txt, ob Suchmaschinen-Bots von der Seite ausgeschlossen werden. -> hier sauber
- Werden Seiten mittels noindex gekennzeichnet? In der Datei oder über den Header? -> nein
- Gibt es einen fehlerhaften Canonical? -> nicht optimal: Die Canonicals sind relativ und nicht absolut gesetzt
- Gibt es fehlerhafte hreflang-Tags? -> nein
- Wie ist der HTTP-Statuscode der einzelnen Webseiten? -> Statuscode 200, also alles in Ordnung
Bei den beiden Webseiten sind alle Punkte sauber. Bis auf die relativ gesetzten Canonicals war alles im grünen Bereich. Aber bewirken relativ gesetzte Canonicals ein komplettes Auslisten aus Google? Kann ich mir eigentlich nicht vorstellen. Also weiter suchen.
Auf den Webseiten scheint augenscheinlich alles in Ordnung zu sein. Liegt der Fehler vielleicht bei Google oder bei dem was Google sieht?
Wenn man Zugriff auf die Webmaster Search Console einer Webseite hat, bietet sich ein tiefgehender Blick darin an. Als externer Betrachter habe ich diesen Einblick leider nicht. Also muss ich mir anders helfen.
Der Screaming Frog SEO Spider bietet die Möglichkeit an, den übermittelten User-Agent zu ändern. Also fix den User-Agent auf den Google-Bot gewechselt und auf Start geklickt.
Bingo, es gibt einen Fehler. Der SEO Spider gibt einen HTTP Status Code 403 (Zugriff verboten) zurück.
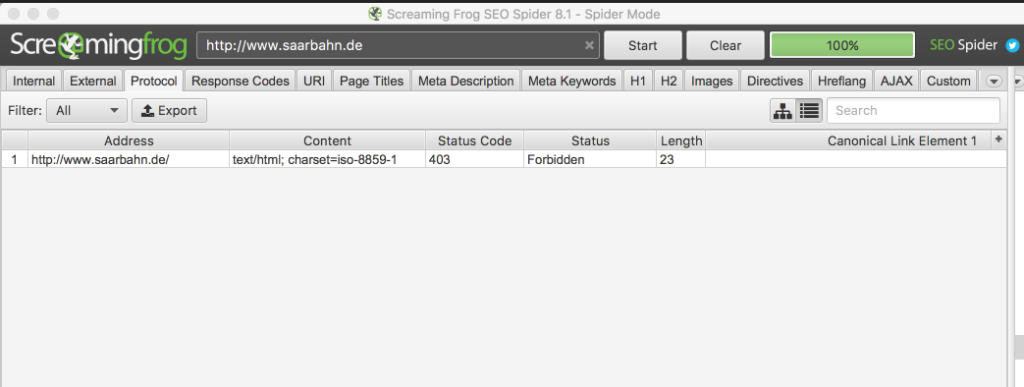
Ruft man die Seite im Browser auf wird die Seite angezeigt – ruft aber der Google Bot die Seite auf, dann wird der Statuscode 403 übermittelt. Das ist natürlich denkbar schlecht. Google sieht also gar nicht die Inhalte, sondern nur die Fehlermeldung. Also listet Google die Seite nach und nach aus.
Warum für den Google-Bot ein 403 angezeigt wird, kann ich von außen nicht begutachten. Vielleicht liegt es am CMS, an einem Spam-Schutz-Plugin oder an was ganz anderem.
Ich will keinem Kollegen an den Karren fahren oder jemanden schlecht reden. Solche Fehler können immer Mal passieren. Manchmal ist es nur ein Klick oder eine Zeile HTML-Code, die so etwas bewirken können. Im Netzt gibt es unzählige Beispiele von solchen Fehlern. Interessant an diesen beiden Beispielen aus Saarbrücken ist aber, dass der Fehler scheinbar schon ein paar Wochen online ist und noch nicht behoben wurde.
Meine Empfehlung
- Bei technischen Änderungen oder Design-Anpassungen sollte ein SEO konsultiert werden.
- Die Google Search Console (ehemals Google Webmaster Tools) sind für Webseiten-Betreiber essentiell. Hier werden viele Fehler angezeigt, insbesondere Crawling-Fehler.
- Überwachen Sie bei wichtigen Webseiten die Besucherströme und setzen sich Alerts, die bei einem Traffic-Abfall Alarm schlagen. Oder lassen Sie Ihren SEO Ihre Webseite überwachen.